Building Text-to-Speech Software Based on Amazon Polly
Unveil how we delivered a solution that empowers publishers to convert text to speech, generating revenue from their content.

Executive summary
Our Customer
Trinity Audio is a company that specializes in developing an AI-driven ecosystem of solutions that help manage audio experiences for publishers and content creators. These solutions encompass a wide range of features, including voice editing, content discovery, virtual assistant skills, and data analytics among many others.
The Obstacles They Faced
Trinity Audio needed a web audio player that could perform several key functions: converting text to speech (TTS), storing and delivering audio content, resolving pronunciation issues via lexicons, while also enabling publishers to monetize their articles.
How We Helped
We delivered a comprehensive solution that empowered publishers to seamlessly convert text to speech, generate revenue from their content, and enhance the user experience for content consumers. The web audio player addressed platform integration challenges, enabled efficient audio conversion, and ensured accessibility for users by improving pronunciation, ultimately creating a new efficient channel for publishers to engage with their audience.
The Challenge
This project aimed to provide solution users with an audio player capable of turning web-based text content into spoken words. This endeavor aimed to benefit content publishers by providing a novel means of connecting their audience.
Multifunctional web audio player
The audio player should be designed to serve as the crucial link between the text content on web pages and its auditory rendition. It needed to be versatile, and capable of accommodating various types of web content structures and styles, including static, dynamic, delayed, and URL-based text.
Powerful API
The primary role of the API component is to convert the extracted text into audio. However, it goes beyond this function and demonstrates exceptional capabilities including text chunking, text hashing and caching, audio storing and customizing, translation support, voice styling, lexicon and Speech Synthesis Markup Language (SSML) support.
Dedicated QA framework
As an integral part of this project, the testing framework has to be meticulously designed to cover a range of critical aspects.
These encompass:
- Automation tests to guarantee accurate text extraction and the exclusion of unwanted elements from publishers’ sites, a measure that prevented the unnecessary creation of new audio files.
- Unit tests to provide comprehensive coverage of various functionalities, including text handling, SSML, voices, and translations.
- API (End-to-End) tests to ensure the generation of expected audio, adapting to the evolving nature of AWS Polly’s service by monitoring file size and audio length for relevancy.
The Solution
The solution we delivered to our client under this project consists of 3 core parts:
- The Audio Player that is able to grab appropriate text from a webpage and send it to the API.
- API that ensures and handles audio processing.
- Quality assurance (testing) system that ensures the system’s stability.
The Player
The player supports different kinds of integrations, and different kinds of text availability, such as static, dynamic, delay, and URL-based content. It also has a capability to extract corresponding text while filtering out unnecessary HTML elements. One more functionality enables grabbing pauses based on HTML markup. Finally, the text is normalized and transmitted to the API for further processing.
A detailed description of the Player’s work
- So as to extract text from a web page, we employ CSS selectors specific to each publisher. This approach requires a well-structured HTML layout, ensuring that we can configure appropriate CSS selectors to accurately retrieve the desired text.- The Player has additional functionality to filter out elements that are part of the CSS selector but should not be read by our player and can not be filtered out by the CSS selector itself;
– Dynamic elements that might be inserted into a page, like ads, promotions, etc. are to be filtered as well, in order not to make audio regenerated (See below);
– As per text normalization: in case of using special extended Unicode characters, we convert them into regular ASCII/Unicode symbols so TTS can read them;
– The Player provides the ability to read text with appropriate pauses based on HTML markup, e.g. pause after title, or pause after block element to list just a few.
– The Player’s functionality also allows grabbing the title and article text separately along with metadata.
- Another feature is translation support so that users can select an audio language directly on a player.
- The Player enables different publisher integrations, such as regular web pages (via ‘script’ tag or ‘iframe’), WordPress and other blog services.- Different types of text availability are supported as well, such as text already presented on a page, text loaded after a while, text loaded via AJAX, text loaded by URL and others.
– The last integrated feature is able to handle paywall when a user is logged in.
API
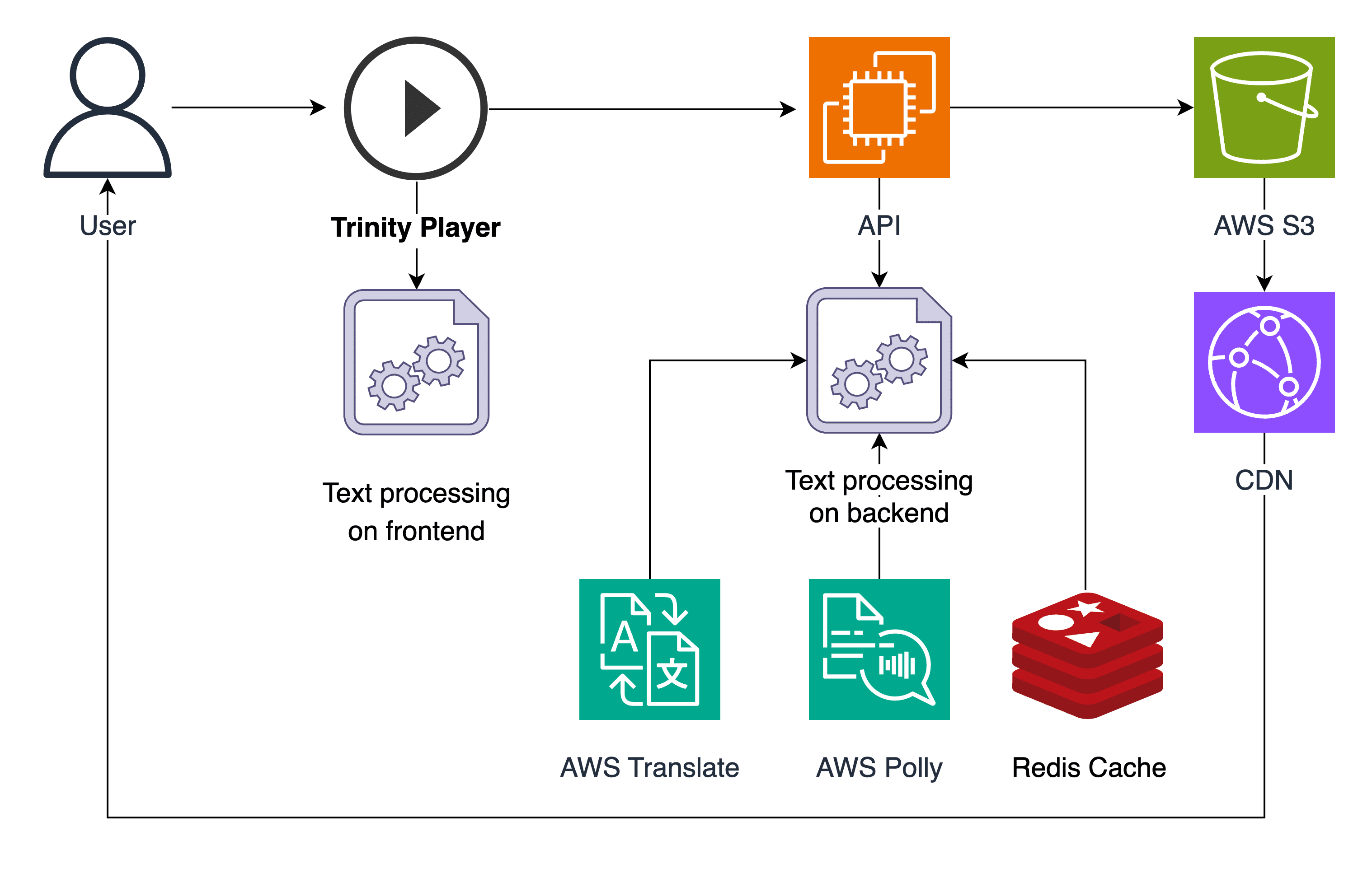
We utilize AWS Polly in order to convert text to audio (text to speech/TTS). Since AWS Polly has a limited size of the input text, we split larger texts into chunks and send them to TTS in parallel. Then, once all chunks are ready, they can be combined to form one entire audio piece. Also known as the concatenated audio, it is later stored in both AWS S3 and AWS Aurora DB (database) and can be accessible to users through a Content Delivery Network (CDN). If audio has to be translated, it is performed in advance.
Additionally, we support different types of voice styles as well as neural and standard engines. Also, we provide the ability to read the text in different variants, such as title, author, pauses, and content, in order to enhance user experience.
In order to determine whether audio should be regenerated due to text modifications, we store a hash of the text for tracking purposes. Subsequently, if the same text is requested, we can readily retrieve it with no need to be regenerated.
In order not to regenerate entire audio each time minor changes are introduced, like spaces, commas, letter cases, and unicode symbols, we have implemented our own logic to determine what range of unicode symbols we track. For caching and storing process data and other related info, we employ Redis.
To accommodate lexicons in case publishers need different pronunciation, we utilize SSML functionality, including ‘say-as’ and ‘phoneme’ tags. That allows us to support correct spelling or advanced IPA if needed. SSML also grants us the flexibility to introduce custom pauses if the situation calls for it. We have established not to use Polly Lexicons functionality due to its limitations (up to 100 lexicons per account).
While working with Speech Synthesis Markup Language (SSML) and text manipulation, you have to keep in mind that you can work with text displayed from RLT (right to left) or LTR (left to right), such as in the case of English. In order to concatenate that text seamlessly you need to detect the text you are currently working with and use special Unicode characters to make it work. This ensures that both RTL and LTR text can be combined effectively.
Testing
We have implemented automation tests to ensure that we still read the correct text and not unneeded elements (such as dynamic blocks or ads) from publishers’ sites, so that we do not regenerate new audio for each change. Also, the features include an extensive testing coverage in order to prevent any unintentional disruptions to the player and audio creation functionality.
We have taken measures to ensure our code works as expected through a combination of unit and API (End-to-end) tests. Unit tests check various functionality aspects related to texts, SSML, voices, translations, and more. Such tests are in place to validate the correctness of individual components within our codebase.
Our E2E tests focus on the expected audio generation. However, since audio is binary and AWS Polly cannot return the same audio all the time due to service updates and continuous improvements, we check if file size/audio length is relevant. It is important to note that audio size cannot be exact either, so some file size deviation is allowed.
Text-to-Speech Software – Architecture Diagram
Amazon Web Services Utilized







The Results
What We Achieved Together
We have helped our client to develop a versatile solution that allows the publishers to seamlessly integrate web audio player into different kinds of platforms. This player accommodates various types of text availability, enabling publishers to convert their articles to audio format.
Our solution also supports translations and improves user experience through a wide variety of voices, voice styles and ability to change pronunciation, and variant readings. Audio generation process is now also streamlined, ensuring fast and ready available audio content for users.
- Integration versatility
The web audio player we created seamlessly integrates with diverse platforms, accommodating variations in text availability and content types. - Efficient audio conversion
Ensuring fast and efficient text-to-speech (TTS) conversion while managing translations and providing a variety of voices and voice styles. - Pronunciation improvement
Addressing audio pronunciation issues via lexicons to deliver high-quality auditory content. - Robust testing framework
Dedicated testing framework and mechanisms collectively played a crucial role in upholding the system’s performance and the quality of the user experience. - Monetization support
Enabling publishers to monetize their articles through the audio content, creating a new revenue stream.
Why Romexsoft
Partner with Us to Build Modern Application
Romexsoft is an AWS-certified Consulting Partner, trusted Software Development Company and Managed Service Provider, founded in 2004. We help customer-centric companies build, run, and optimize their cloud systems on AWS with creative, stable, and cost-efficient solutions.
Our key values
- Delivery of quality solutions
- Customer satisfaction
- Long-term partnership
We have successfully delivered 100+ projects and have a proven track record in FinTech, HealthCare, AdTech, and Media industries.
Romexsoft possesses a 5-star rating on Clutch due to its strong expertise, responsiveness, and commitment. 60% of our clients have been working with us for over 4 years.
Related Success Stories

