Published: October 6, 2024;
9 min read
| Updated: January 14, 2026
Commentary from data scientist on how to improve diagnosis with clustering analysis models (DBSCAN), classification models, and forecasting models (using regression).

How long did your last chat with a doctor was?
Let me guess – around 10-15 minutes. That’s exactly how much time your average clinician can spare on a patient to assess the complaints, scroll through the past records, and suggest a possible diagnosis.
In critical cases, the time is even more limited and the decisions must be made within minutes.
EHR software facilitates this process and offers all the essential patient information on the platter.
The question, however – is this information enough?
After all, the annual cost of medical errors still remains close to $17.1 billion, not to mention the non-financial liabilities a professional will have to deal with after concluding a wrong diagnosis and assigning incorrect treatment.
To understand the nature of errors, let’s take a look at the standard medical diagnosis procedures framework:
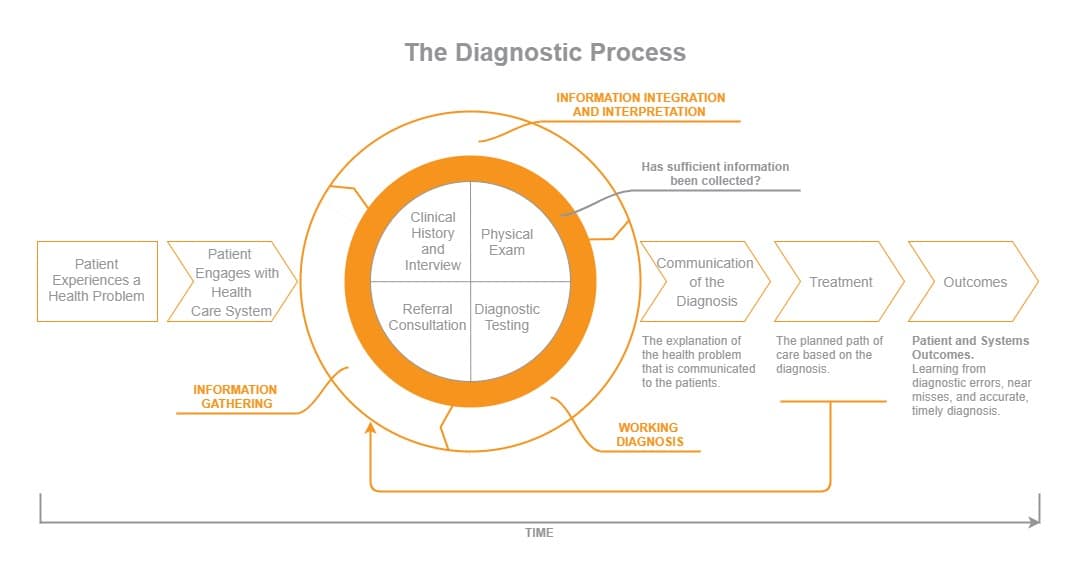
Source: http://www.nationalacademies.org/
As you can see from the diagram, information integration & interpretation is the most important stage during the diagnostic process.
Yet, during this stage, most medical errors occur. According to the Agency of Healthcare Research and Quality, doctors and clinicians are often prone to cognitive bias and incorrect applications of heuristics (“rules of thumb”) during the diagnostic stage. Specifically, the next errors are the most common:
One of the main applications of machine learning in medicine is to eliminate these biases and help answer this question with higher accuracy:
“Has Sufficient Information Been Collected?”
“Smart” machine learning algorithms are already used across different industries to replace repetitive, costly, and time-consuming tasks.
Their advantage is that, unlike the human eye (and brain), they can capture unforeseen patterns within complex data sets at lightning speed.
In other words – they can determine a certain condition or a health risk much faster and with higher accuracy. Additionally, machine learning algorithms for healthcare data analytics can churn all sorts of forecasts such as the likelihood of developing a certain condition; being re-hospitalized in X days and even suggest the possible patient’s response to a new drug.
To give you some better context, here are some of the latest health tech trends on how to improve diagnosis in healthcare:
Using machine learning and pattern recognition to assist diagnosis – an algorithm developed by Google can identify cancerous cell patterns in slides of tissue and detect breast cancer. The algorithm showed 89% accuracy, compared to a 73% accuracy score of a human pathologist.
Stanford Artificial Intelligence Laboratory trained their algorithm to visually recognize and diagnose potential skin cancer. During benchmark tests, the algorithm matched the performance of a human dermatologist.
Create health risk predictions based on existing data from similar cases. Scientists from Indiana University-Purdue University Indianapolis deployed a machine learning algorithm capable to predict leukemia remission with 100% accuracy. Relapses were correctly predicted as well with 90% accuracy. The model was trained to analyze bone marrow data and medical histories of AML patients and compare it to blood data from healthy individuals.
Forecast patient admission rates. Assistance Publique-Hôpitaux de Paris (AP-HP) has created an algorithm to predict patient admission rates on a daily basis. By utilizing internal and external data sets – public statistical data plus 10+ years worth of hospital admission records – the institution has managed to predict how many patients will come through the door each hour, and predictions can be made up to 15 days in advance.
This way, the hospital can optimize and allocate human resources as per demand and improve patient outcomes.
These examples perfectly illustrate the areas that could be addressed and improved with machine learning. The next logical step, however, is to understand how exactly those algorithms function.

The section below will illustrate three different approaches to machine learning in the healthcare domain, along with the positive outcomes they could bring for healthcare institutions.
The special emphasis is placed on improving the diagnosis process specifically.
Big data in healthcare is getting really big.
While EHR systems were designed specifically to cope with this issue – store and categorize all the incoming and existing patient data. Modern EHR software is capable to automate a significant chunk of manual work such as:
Then, it can process these piles of unstructured data (raw, scattered entries) into structured data – information with a top-level of organization, which is easy-to-search and operate.
In order to leverage that data and turn it into actionable insights, you will need to utilize machine learning.
In the book, “Machine Learning in Medicine – a Complete Overview“, researchers from the Netherlands Ton Cleophas and Aeilko Zwinderman have outlined 80 machine learning applications in healthcare.
The first, chapter specifically outlines how to improve diagnosis and reduce diagnostic error with the help of cluster and classification models.
Clustering allows you to identify similar sets of observations and group them into respective subsets (clusters). All the clusters bear similar characteristics in some sense. Basically, you teach the algorithm to identify whether certain relationships exist between two data entries and group them accordingly.
For instance, you have survey results/records from a demographic group of patients suffering from different levels of mental depression. Based on the existing data, you can train the algorithm to identify and categorize all the patients in respective sub-groups (based on their current level of depression) and then predict subgroup membership for future patients with similar symptoms.
The benefits, in this case, are the following:
Next, the classification function will help you improve data analysis even further. Specifically, it allows you to establish to which class a new data entry belongs.
The next examples illustrate what could be achieved with simple classification functions:
Additionally, our Big Data engineers suggest using DBSCAN (Density-based spatial clustering of applications with noise) when you need to get through noisy data (aka meaningless entries that could not be rendered by the machine) and classify all the entries at disposal at the same time.
Decision trees can be leveraged both in the diagnosis process and to determine the best predictors of health risks.
For example, you could explore the correlation between inflammatory markers and pneumonia severities.
Or analyze cardiovascular autonomic neuropathy data obtained through sensors to determine whether a patient has any signs of diabetes or not.
In the latter case, applying the decision tree and ensemble methods could help you determine the right treatment plan and diet for the patient.
As Dr. GP Pulipaka notes, you will need to apply the next methods:
For computing, you can use Spark ML, which incorporates methods for processing the data, which is formed as a Dataset. A dataset that can support a variety of data types (text, vectors, images, etc.) under a unified dataset concept and allows combining multiple algorithms into a single pipeline (workflow). This increases the processing speed and reduces the chances of errors at the same time.
More read: AWS HIPAA Compliance: Best Practices Checklist
In data mining, the regression model is used to predict a certain number based on the existing data.
For instance, it could help you answer such questions as:
Considering that you already have a dataset labeled with numbers (past records on costs or admission days of similar patients), you will then need to “feed” your algorithm with this data plus additional demographic information such as age, gender and so on.
Using regression, you can then predict how likely the person will be re-hospitalized and within what period of time.
Again, you can use Apache Spark (the framework we swear by at Romexsoft) to conduct simultaneous calculations of different problem types at an excellent speed.
Using a regression model can help hospitals to optimize their billing cycles and patient flow management by predicting the chance of re-hospitalization for instance or deterring how long a certain patient will need to stay in the ICU. Doctors, on the other hand, can benefit from receiving immediate insights about certain new and existing patients (e.g. whether a person is overweight/underweight; whether their leucocytes numbers are within the normal range compared to the peer group with similar symptoms/chronic illness and so on).
Romexsoft has previously helped healthcare startups to develop innovative big data solutions and build “smart” EMR and EHR systems for traditional health care institutions. Get in touch with us to discover how your organization can benefit from adopting machine learning algorithms.



