Published: August 16, 2017;
8 min read
| Updated: March 11, 2026
Discover the benefits of implementing a fraud detection system (apart from catching the fraud) with insights how to build such system.

Fraud detection using data analytics in the banking industry is no longer a trend. It’s the necessity all progressive institutions should embrace.
Allow me to illustrate this with some data.
To satisfy consumer demands, most banks today practice a 98-99% transaction approval rate on credit cards. Certainly, this encourages consumers and other businesses to use, accept, and process card payments in the first place. Yet with no proactive monitoring and fraud prevention mechanisms in place, financial institutions become vulnerable to all sorts of credit card scams.
On a global scale, credit card processing fraud has hit $32.320 trillion in total, with $21.84 billion lost in the US only. This data accounts for all sorts of transitions (online and in person), including transactions at POS, ATMs and those secured by PINs.
E-commerce and online retailers should be on the watch out too. According to Juniper research, online fraudulent transactions in this industry are predicted to reach $25.6 billion by 2020. For comparison, in 2015 this sector lost $10.7 billion to scammers.
The top three hot industries for online fraud and theft are the following ones:
Online lenders should also start paying more attention to fraud protection. ID Analytics report shows that in 2014 these companies had the single highest industry rate for fraud (over 1.2%).
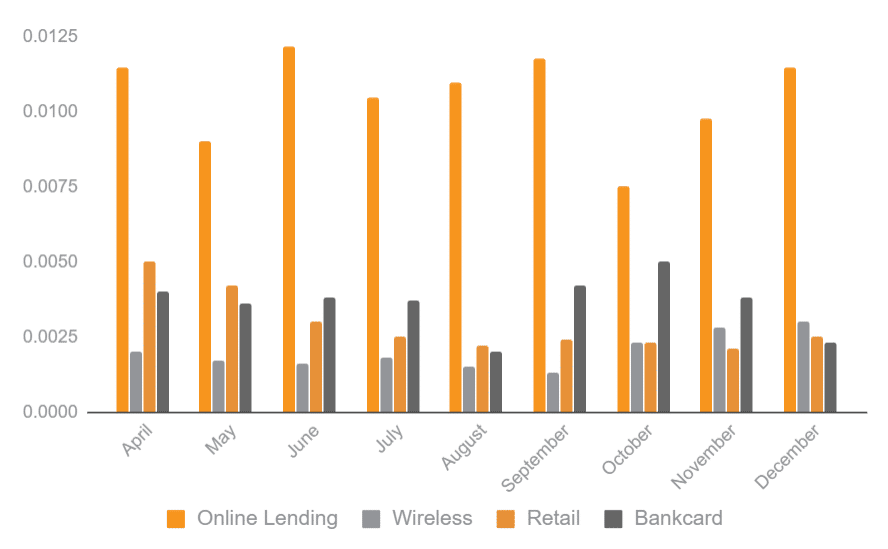
Source: ID Analytics report
Here’s another kicker – proactive bank frauds prevention and detection isn’t just about securing your assets and avoiding losses. Implementing a robust fraud detection system will result in additional benefits:
Better Analytics and Predictive Forecasts: credit card frauds often bear a recognizable pattern. With the help of machine learning, you can train your monitoring system to gather and analyze abnormal patterns and immediately switch to the credit fraud alert mode when things get awry.
Here’s a quick example. The system notices that some Chinese eRetailer is frequently charging AMEX cards issued by your bank. The system can then investigate further into the matter and discover that AMEX cards with a particular BIN number (bank identification number) are being fraudulently used. With a couple of clicks, you can stop all the transactions and mark all the cards with such BIN as compromised. Now imagine how long it would take for a human analyst to notice such pattern and investigate into the matter?
Improved detection. Fraudsters are smart. They constantly deploy new threats to trick your system. But they often build their new threat using bits and pieces from their old endeavors.
You, in turn, can develop a smarter solution that would notice these new trends before they emerge, react accordingly and continuously learn to recognize and prevent similar threats.
Better relationships with the customers. No one wants to be a victim of a credit card fraud. Your customers want to feel confident with their bank. That is why it’s always more comforting when the bank initiates the contact when any sort of unusual activity is detected.
The question that remains is this – how to detect credit card fraud in banking fast and efficiently?
Well, that’s something Romexsoft team has been dealing with for the past few months. We’ve analyzed different fraud detection systems used by banks, took the best strategies, ditched the outdated ones and came up with our own algorithm using Java and Apache Spark.
Big data fans and techies can see the full case study here, which includes a step-by-step tutorial with code snippets. In this post, we’ll summarize the key points of implementing fraud analytics in banking.
Fraud risk management in banks can be implemented using a classification credit card fraud detection model, which is built the following way:
The goal of such model is to be able to distinguish the highest possible True Positive Rate (TPR) and the lowest possible False Positive Rate (FPR) in order to offer accurate forecast and fraud monitoring in banks.
Now, here’s a kick – even a slight number of FPR cases in your classification model can result in a large number of incorrectly classified results. Your model will then classify both True Positive (indeed fraudulent transactions) and a certain amount of False Positive (honest transactions that may resemble fraudulent ones) as fraudulent activity. And then, you will have to manually recheck those incorrectly classified cases. No good, right?
So the prevention of frauds in banks starts with balancing and refining your data first. Next, to train your model even further, you can use different oversampling methods to balance the data you have at hand. (I’ve shared the techniques we used in the case study.)
Considering that you have already given your classifier model enough samples for the initial training, let’s move on to the model estimation stage.
In our case, we used a logistic regression model to obtain predictions for fraudulent cases. To give you more background, here’s an illustration of the classificator we used for that process:
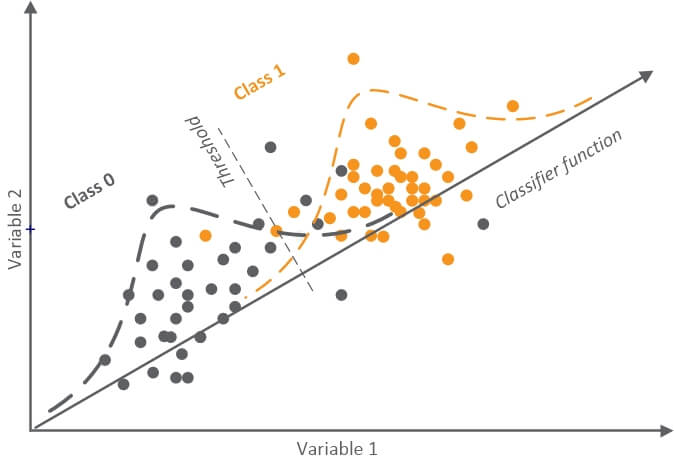
The gray area represents Class 0 (or honest transactions), while the orange side accounts for all the false transactions. But you need to pay attention most of your attention to the threshold.
The key to accurate classification and analysis here is to establish the optimal threshold – the one that would indicate the most difference between variable 1 and variable 2, and at the same time allow us to achieve the lowest possible FPR (False Positive Rate).
Finally, what we found out is that the threshold value significantly impacts the classification results. Specifically, as the threshold increases, the number of identified fraudulent transactions decreases. But, you also reduce the FRP value.
So how do you choose the optimal threshold?
For binary classifications such as this one, the best route is to use Confusion Matrices (show the ratio between FPR and TPR depending on the chosen threshold) and ROC-curves (receiver operating characteristic curves. A ROC-curve will show you the optimal threshold for our classifier).
Here’s an example of how Confusion Matrices will look:
Confusion matrix example
| Actual class | Predicted class | |
|---|---|---|
| Fraudulent | Honest | |
| Fraudulent (recall) | True Positive | False positive |
| Reliable (recall) | False negative | True negative |
And here’s how ROC-curves look:
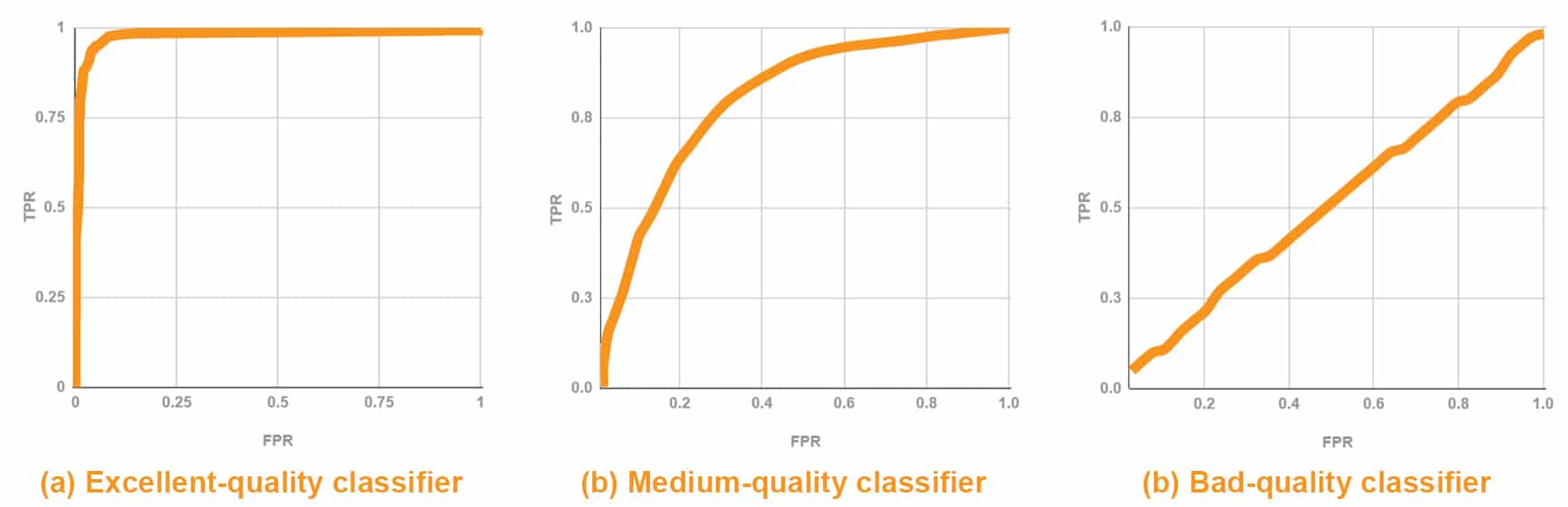
Additionally, to make sure that your classifier is accurate enough, take a look at the Array Under Curve (AUC) index.
Specifically:
A ROC-curve you can see at the picture a. above features an AUC from 0.9 to 1 and the ROC-curve at pic c. has AUC≈0.5.
For our project, that’s how the ROC-curve for the classifier looks:
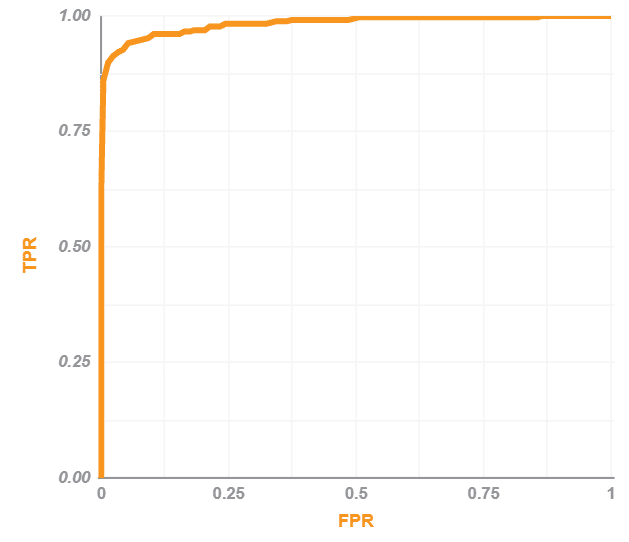
Here, AUC equals 0.9844, meaning that this is an excellent classifier.
Quick Note: The definite benefit of Apache Spark is that you can generate ROC curves with a quick command.
This should have given you the insights in how a credit card security service can be created with Apache Spark. But let’s get back to the real life situation.
We used a classifier model with an AUC = 0.9837 to analyze a dataset of 284.807 transactions, conducted in Europe during two days.
The forecast results can be viewed below:
Confusion matrix for our sample
| Actual class | Predicted class | |
| Fraudulent | Honest | |
| Fraudulent (recall) | 404 | 62 |
| 86.7% | 13.3% | |
| Reliable (recall) | 514 | 269594 |
| 0.19% | 99.81% | |
Here’s how much money that actually stands for:
At the same time, the classifier couldn’t identify a certain amount of fraudulent transactions (approx. 7.600 euro total).
But you could still catch those pesky transactions if you set another threshold for the classifier. From our experience, it makes sense tweaking the algorithm as long as it will cost you less to deploy it compared to the financial loss caused by the non-identified fraud.
In a nutshell, that’s how to prevent frauds in banking. And here’s some more great news – a similar cluster computing system could be trained to perform a vast array of other tasks simultaneously and help you with the following:
Romexsoft Big Data specialists would be delighted to offer more information on how a similar algorithm could be implemented for your business and advise other strategies for creating a powerful fraud management system.



