On-prem to AWS Migration Case Study for Healthcare SaaS
Explore how we delivered an on-prem to AWS cloud migration of a home healthcare SaaS to improve scaling and resilience of operations.

Our Customer
Therapy Management Software
therapyBOSS SaaS platform developed by Pragma-IT makes running a home health business simple and efficient. Built for therapy staffing agencies, early intervention programs, and mobile outpatient practices, it cuts paperwork, lowers costs, and frees professionals to focus on care. With therapyBOSS, clinicians can manage patients and complete tasks anywhere, on any device and even without connection in offline mode.
THE CHALLENGES
On-prem Infrastructure Constraints
Since the product launch, it has grown steadily and continued to evolve technically. At a certain point, we began extending the platform’s on-premises infrastructure by incorporating certain AWS services. Since then, the system architecture has become a kind of hybrid, combining on-premises servers with Amazon’s cloud. As the user base expanded, the core systems load increased and current hybrid infrastructure had reached its capacity limits, and several challenges began to impact both operations and end-users:
- High operational and cost overhead
Running a custom on-prem environment required continuous maintenance of both hardware and software, along with specialized DevOps expertise. Because the platform had to be sized for peak load, the team was forced to provision fixed capacity without elasticity. This led to higher spending, routine manual upkeep, and increased reliance on domain-specific engineers for patching, monitoring, and troubleshooting. - Infrastructure complexity
Operating hybrid infrastructure that spans on-premises systems and AWS introduces additional architectural, operational, and security complexity. Such environments require careful design to minimize latency, dependency issues, and data-synchronization overhead. - Unreliable system communication
Intermittent communication problems between on-premises and AWS components led to disruptions, lowering overall solution reliability and stability. - Scalability barriers
While on-premises infrastructure provides full control, it is difficult to scale computing resources quickly, limiting the ability to meet new demand or support growth. The lack of elasticity makes it challenging to handle sudden demand spikes, as hardware must be purchased and installed in advance. As a result, overprovisioning becomes common in an effort to “plan ahead,” which increases costs. - Technology and innovation limitations
The therapyBOSS team found that their on-premises environment could no longer keep pace with technological change or evolving business needs. Experimenting with modern capabilities such as AI-driven analytics, containerization, or autoscaling would have required costly hardware upgrades. - Prolonged incident recovery
When the on-prem setup experienced downtime, engineers had to investigate issues manually, restore services, and validate the system component by component. This slowed recovery, extended service interruptions, and pulled the team away from product development priorities. - Customer impact from downtime
Each outage affected therapyBOSS clients, clinicians, who depended on the platform for daily patient management and documentation. Repeated interruptions created operational delays for care teams and reduced confidence in the platform’s reliability.
THE SOLUTION
AWS Cloud Infrastructure Adoption
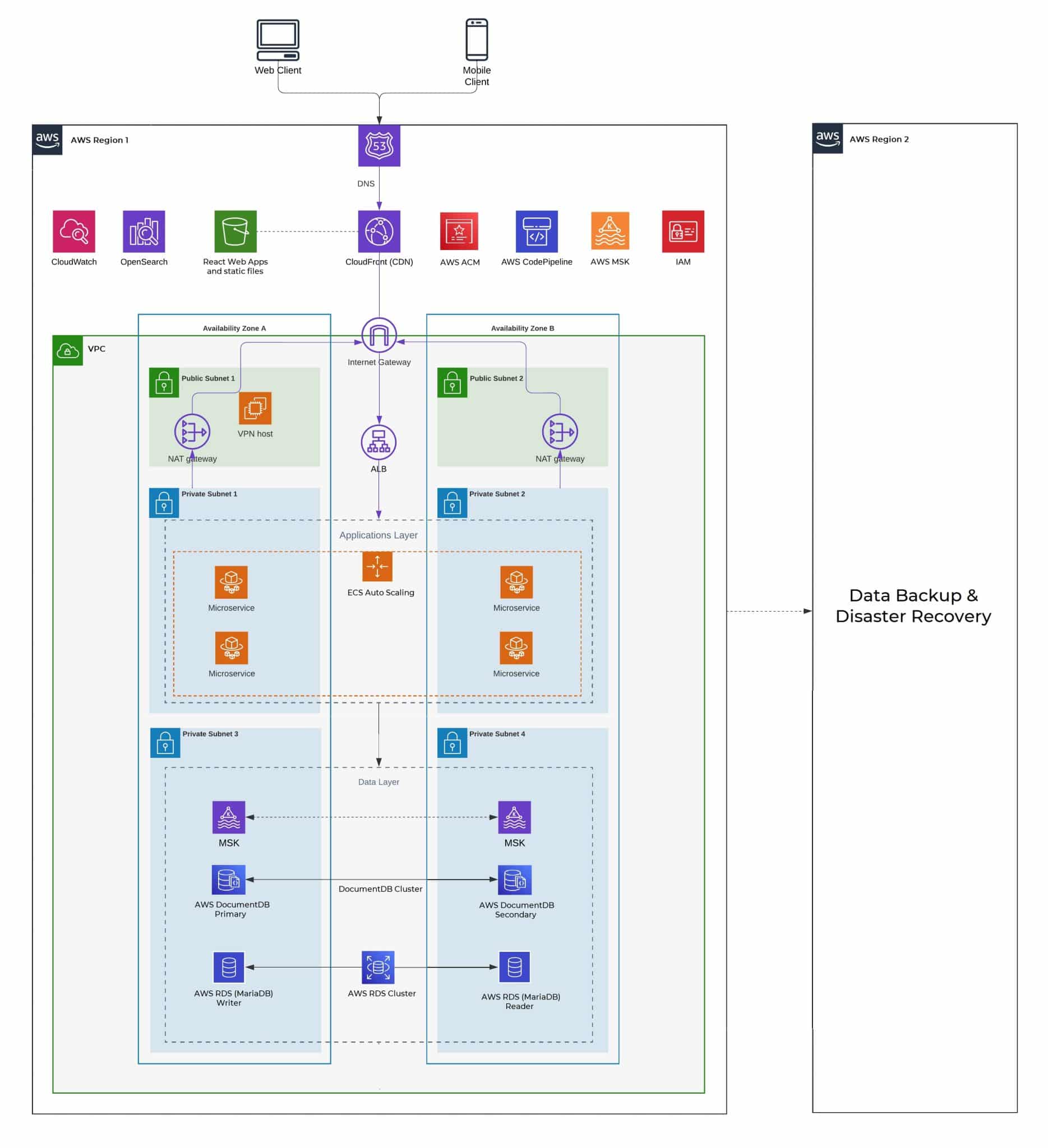
To meet growing demands for scalability and agility, our dedicated engineering team migrated the infrastructure to AWS Cloud using the AWS Cloud Adoption Framework (CAF) to modernize its legacy on-premises environment.
- Envision and Align
At the initial stage of this project, we collaborated with the TherapyBOSS team to clarify modernization priorities, define desired business outcomes, and establish the governance model for the AWS migration. - Migration Launch
The core cloud environment and core services were built to support workloads securely and efficiently.- Infrastructure as Code (IaC): Terraform and Terragrunt automated cloud setup and management, reducing manual efforts, and improving reliability.
- Account management with AWS Organizations: The Cloud Solution Architect prepared a structured multi-account hierarchy to separate development, testing, and production, ensuring stronger governance, clearer access control, and safer deployments.
- AWS Control Tower: By using Account Factory engineers created standardized accounts for development, staging, and production. Preventive and detective guardrails were applied to enforce company policies such as restricted access, encryption, and logging across accounts.
- Dedicated non-production accounts: Separate AWS accounts were established for development and testing, enhancing security and allowing scaling without disrupting production workloads.
- Resilience
The new infrastructure keeps the system available, enables fast recovery, and maintains reliable operation even during failures, disruptions, or sudden changes in demand.- High availability (HA): The AWS Solution Architect used Multi-AZ deployments, Elastic Load Balancers, Auto Scaling, and other AWS services to ensure the system stays online when individual components fail.
- Disaster recovery (DR): DevOps specialists prepared for large-scale disruptions such as regional failures or outages, by implementing multi-region backup and restore strategies.
- Scalability
Cloud adoption was expanded across workloads while enabling flexible growth.- Containerized applications: DevOps engineers used AWS CodePipeline to automate builds and deployments, streamlined delivery, and enabled rapid rollbacks
- Auto scaling configuration: We implemented AWS Auto Scaling policies to maintain CPU utilization between 60–70% to scale tasks up/down automatically. Scheduled scaling was also configured to increase capacity during peak business hours. In addition, health checks were integrated with the Application Load Balancer to ensure that only healthy instances remained in rotation.
- Optimization
Performance and delivery were improved while operational risks were reduced through automation and observability.- CI/CD pipeline: AWS CodePipeline used to automate builds and deployments, streamlined delivery, and enabled rapid rollbacks.
- Monitoring and alerting: Grafana, OpenSearch, and AWS CloudWatch provided end-to-end monitoring, alerting, and resource usage tracking.
Software Infrastructure Before Migration

Healthcare SaaS AWS Infrastructure After Migration
THE RESULTS
Operational Resilience with Scalable Growth
In this AWS cloud migration case study, Romexsoft migrated therapyBOSS from on-premises infrastructure to AWS following AWS best practices, helping the platform overcome infrastructure constraints and achieve measurable operational improvements:
- Improved reliability and customer trust
By replacing on-premises with AWS environment and introducing robust monitoring, the platform now delivers stable performance with minimal downtime. This consistency strengthens confidence among therapyBOSS users who rely on the system for daily operations. - Cost and effort efficiency
Migrating from fixed-capacity hosting to elastic AWS services allowed resources to scale up/down with demand. Being able to scale on demand reduced waste, lowered operational overhead, and ensured infrastructure spending matched actual usage. - Accelerated release cycles and recovery
Automated CI/CD pipelines significantly improved delivery speed by standardizing builds, deployments, and rollbacks. The client’s engineering team can now release updates and new features with predictable timelines, reducing deployment risk. - Reduced maintenance with greater scalability
Infrastructure as Code and AWS-managed services cut down on manual tasks, freeing engineers to focus on product enhancements. Containerized applications and dedicated accounts further simplified scaling across environments, ensuring the system can evolve alongside business growth. - Enhanced visibility into performance
With Grafana, OpenSearch, and CloudWatch in place, the engineering team gained unified insights into performance, resource consumption, and potential risks. This proactive observability supports both operational stability and long-term optimization.
WHY ROMEXSOFT
Trusted AWS Cloud Migration Partner
Romexsoft is an AWS migration company and an AWS Advanced Tier Services Partner. Our engineers migrate SaaS platforms from on-premises infrastructures to AWS and modernize cloud architecture.
Our track record allows us to deliver cloud migrations that are structured, reliable, and aligned with your goals:
- Ensuring Rehost, Replatform, and Refactor types of migrations from on-premises environments to AWS
- Delivery of HIPAA- and GDPR-ready environments for healthcare and SaaS platforms
- Modernization of mission-critical SaaS workloads with measurable gains in uptime, performance, and release speed
- Supporting post-migration reliability through a three-layer monitoring setup and comprehensive managed DevOps support.


Frequently Asked Questions
We follow AWS migration guidance and design the process around controlled cutovers, continuous synchronization, and pre-validated environments. Before traffic is moved, the full AWS environment is provisioned with Terraform, dependencies are synchronized, and health checks, logging, and guardrails are verified.
Our engineers run a pilot migration to validate behavior under real conditions, then use staged cutover windows, data sync mechanisms, and load balancer routing to shift traffic only when all components are healthy. Monitoring is active throughout the transition, so if any issue appears, the team can roll back immediately.
Before migration, we create a cost projection using the AWS Pricing Calculator and a TCO (Total Cost of Ownership) analysis recommended in AWS CAF. We map current on-prem resources and consumption (compute, storage, databases, and network usage) to equivalent AWS services to understand likely monthly spend.
To model savings, we compare this projection with the full on-prem TCO: hardware purchases, maintenance, data-center expenses, support contracts, and the operational effort needed to run the environment. Elastic scaling and pay-as-you-go pricing mean the platform no longer needs purchasing in advance resources, which further reduces costs.
We look at how the workload behaves and how it will be operated long term rather than treating ECS, EC2, or Lambda as interchangeable.
For a migrated SaaS, we typically:
- Choose ECS when we want a container-based model with predictable runtimes, stable connections (e.g., web apps, APIs), and a clear path to gradual modernization.
Use EC2 when the workload is more lift-and-shift, tightly coupled to the OS, or requires specific system-level control, custom runtimes, or legacy components that are not yet container-ready to perform migration without rewriting the whole application.
- Consider Lambda for event-driven, short-lived tasks (background jobs, scheduled processing, integrations) where functions can scale independently and benefit from fully managed execution.
In practice, we often combine them: EC2 or ECS for the core application, and Lambda for supporting jobs, choosing each option based on runtime characteristics, latency requirements, integration patterns, and operational model.
After migration, we offer an ongoing support model that can be activated if the client needs continuous operational coverage. Depending on the requirements, we provide 24/7 DevOps support with both L2 and L3 engineering capabilities.
The service includes defined SLAs, monitored environments, and clear escalation paths. L2 engineers handle day-to-day alerts and operational tasks, while L3 specialists address complex incidents and architectural issues.
We deliver this managed support through three tiered packages, designed for emerging, mid-sized, and enterprise organizations, each with defined response times, a set number of support cases, and a corresponding pool of DevOps engineering hours.
